- Docs
- /
Analysis
06 Jun 2022 20811 views 0 minutes to read Contributors ![]()
![]()
![]()
![]()
The following areas can be configured
| Area | Covers |
| Server | The SQL Server to be analyzed |
| Include/Exclude | Filters to include databases and tables and filters to exclude tables |
| Create/Unused Indexes | Decision fields when indexes must be created, disabled or dropped |
| SQL Server Options | Options to be used in the create and alter statements of indexes |
Server
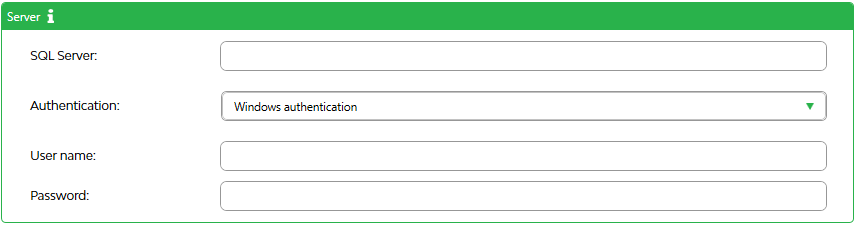
SQL Server
The SQL Server where AIM will perform his analysis on. SQL Server can be specified as 1.1.1.1, 1.1.1.1,1433, SERVER, SERVER\INSTANCE.
On this server SQL Server needs to be installed and the computer from where AIM is started need to have (firewall) access to the server and SQL Server.
As soon as a servername is entered, AIM tries to make a connection to it. When the Authentication, User name, Password is changed AIM tries to automatically reconnect to the server.
Authentication
Possible options:
| Windows authentication | The windows username is used to connect to the server. User name and Password are obsolete in this case |
| SQL Server authentication | The User name and Password are required in this case |
Include/Exclude
Filters to determine which databases and tables should be included and which tables should be excluded from analysis.
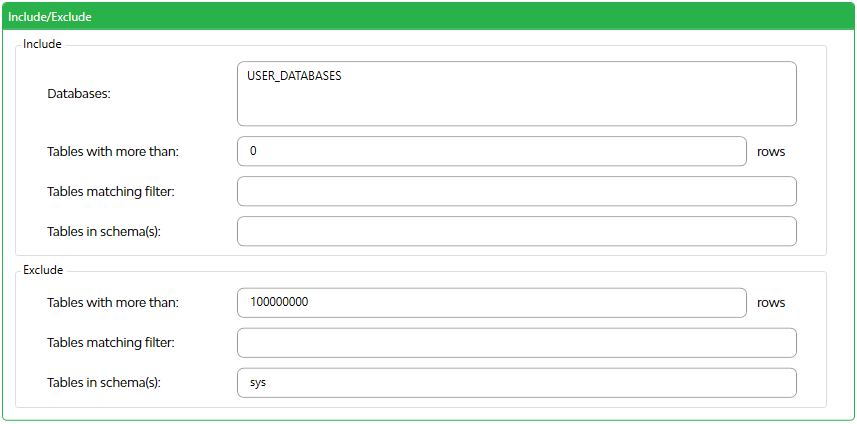
Include - Databases
Select databases. The keywords SYSTEM_DATABASES, USER_DATABASES, ALL_DATABASES, and AVAILABILITY_GROUP_DATABASES are supported. The hyphen character (-) is used to exclude databases, and the percent character (%) is used for wildcard selection. All of these operations can be combined by using the comma (,).
| Value | Description |
|---|---|
| SYSTEM_DATABASES | All system databases (master, msdb, and model) |
| USER_DATABASES | All user databases |
| ALL_DATABASES | All databases |
| AVAILABILITY_GROUP_DATABASES | All databases in availability groups |
| USER_DATABASES, -AVAILABILITY_GROUP_DATABASES | All user databases that are not in availability groups |
| Db1 | The database Db1 |
| Db1, Db2 | The databases Db1 and Db2 |
| USER_DATABASES, -Db1 | All user databases, except Db1 |
| %Db% | All databases that have “Db” in the name |
| %Db%, -Db1 | All databases that have “Db” in the name, except Db1 |
| ALL_DATABASES, -%Db% | All databases that do not have “Db” in the name |
Include - Tables with more than # rows
Minimum amount of rows a table should have to be included in the analysis. If you leave this field blank all tables will be included.
Include - Tables matching filter
Table names you want to include separated by comma's. You can include % to specify filter. If you leave this field blank all tables will be included.
Include - Tables in schema(s)
Schema's that you want to include separated by comma's. If you leave this field blank all schema's will be included.
All conditions have to be met.
Exclude - Tables with more than # rows
Maximum amount of rows before a table gets excluded from the analysis. If you leave this field blank this condition is not tested.
Exclude - Tables matching filter
Table names that you want to exclude from Analysis separated by comma's. You can include % to specify filter. If you leave this field blank this condition is not tested.
Exclude - Tables in schema(s)
Schema's that you want to exclude from Analysis separated by comma's. If you leave this field blank this condition is not tested.
Create / Unused indexes
Conditions for the analysis to decide when to propose new indexes and when to propose disable / drop indexes.
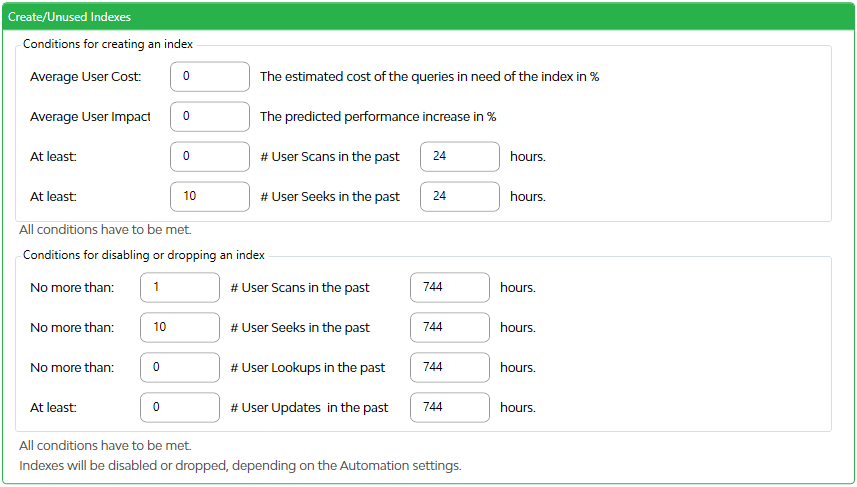
Conditions for creating an index
All conditions have to be met.
Average user cost
avg_total_user_cost tells you how “expensive” SQL Server thought the queries were who wanted this index
When SQL Server optimizes a query, it does a quick estimate of how much work it’s going to be. This is called the query’s “cost”.
Cost is always an estimate in SQL Server. The cost isn’t updated after the query runs to reflect how expensive anything actually was. Even if you’re looking at an “actual” plan, the “actual” parts are just rowcounts.
And “cost” isn’t a measurement of anything we’re familiar with, like seconds. I like to think of it as just “QueryBucks”, the weird currency of the SQL Server optimizer.
The avg_total_user_cost column tells you whether SQL Server guessed that these queries were very cheap (say .0009 querybucks), or more expensive (say 500 querybucks).
It doesn’t tell you anything about whether or not that guess was correct. The optimizer sometimes vastly under or over guesses cost.
Average User Impact
avg_user_impact tells you a percentage that SQL Server guesses the index would reduce that estimated cost
This column is a guess about a guess!
Let’s say the query plan that SQL Server settled on for my query had an estimated cost of 500 querybucks. But SQL Server thought an index might make the query faster. It does a quick guess about how much faster it will make.
So if you see 99 for avg_user_impact, SQL Server thought that the index would drop the cost by 99%. Usually a high number like 99 in this column means that the query was scanning a large index, and the optimizer thought an index could allow it to do a very targeted seek operation instead.
At least # User Scans in the past # hours
Number of scans caused by user queries that the recommended index in the group could have been used for.
At least # User Seeks in the past # hours
Number of seeks caused by user queries that the recommended index in the group could have been used for.
Conditions for disabling or dropping an index
All conditions have to be met. Wether an index is adviced to be disabled or dropped is specified in the Automation tab under Actions.
No more than # User Scans in the past # hours
Number of scans caused by user queries that the recommended index in the group could have been used for.
No more than # User Seeks in the past # hours
Number of seeks caused by user queries that the recommended index in the group could have been used for.
No more than # User Lookups in the past # hours
Number of bookmark lookups by user queries.
At least # User Updates in the past # hours
Number of updates by user queries. This includes Insert, Delete, and Updates representing number of operations done not the actual rows affected. For example, if you delete 1000 rows in one statement, this count increments by 1
# Hours
The hours must be specified in whole numbers
SQL Server Options
Extra parameters added to the CREATE or ALTER statement.
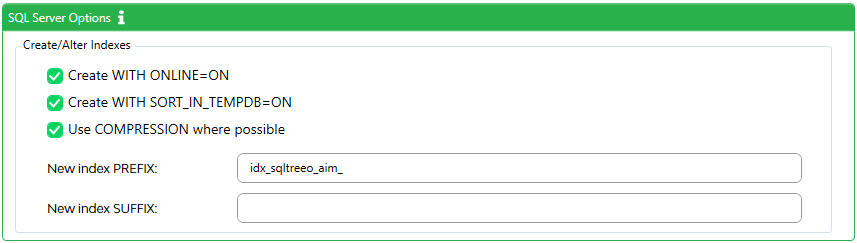
Create with ONLINE=ON
ONLINE = { ON | OFF }
Specifies whether underlying tables and associated indexes are available for queries and data modification during the index operation. The default is OFF.
Important
Online index operations are not available in every edition of MicrosoftSQL Server. For a list of features that are supported by the editions of SQL Server, see Editions and Supported Features for SQL Server 2016.
ON
Long-term table locks are not held for the duration of the index operation. During the main phase of the index operation, only an Intent Share (IS) lock is held on the source table. This enables queries or updates to the underlying table and indexes to proceed. At the start of the operation, a Shared (S) lock is held on the source object for a very short period of time. At the end of the operation, for a short period of time, an S (Shared) lock is acquired on the source if a nonclustered index is being created; or an SCH-M (Schema Modification) lock is acquired when a clustered index is created or dropped online and when a clustered or nonclustered index is being rebuilt. ONLINE cannot be set to ON when an index is being created on a local temporary table.
OFF
Table locks are applied for the duration of the index operation. An offline index operation that creates, rebuilds, or drops a clustered index, or rebuilds or drops a nonclustered index, acquires a Schema modification (Sch-M) lock on the table. This prevents all user access to the underlying table for the duration of the operation. An offline index operation that creates a nonclustered index acquires a Shared (S) lock on the table. This prevents updates to the underlying table but allows read operations, such as SELECT statements.
For more information, see Perform Index Operations Online.
Indexes, including indexes on global temp tables, can be created online except for the following cases:
- XML index
- Index on a local temp table
- Initial unique clustered index on a view
- Disabled clustered indexes
- Columnstore indexes
- Clustered index, if the underlying table contains LOB data types (image, ntext, text) and spatial data types
- varchar(max) and varbinary(max) columns cannot be part of an index. In SQL Server (Starting with SQL Server 2012 (11.x)) and Azure SQL Database, when a table contains varchar(max) or varbinary(max) columns, a clustered index containing other columns can be built or rebuilt using the ONLINE option. Azure SQL Database does not permit the ONLINE option when the base table contains varchar(max) or varbinary(max) columns
For more information, see How Online Index Operations Work.
Create WITH SORT_IN_TEMPDB=ON
Applies to: SQL Server (SQL Server 2008 and later) and Azure SQL Database
Specifies whether to store temporary sort results in tempdb. The default is OFF except for Azure SQL Database Hyperscale.For all index build operations in Hyperscale, SORT_IN_TEMPDB is always ON, regardless of the option specified unless resumable index rebuild is used.
ON
The intermediate sort results that are used to build the index are stored in tempdb. This may reduce the time required to create an index if tempdb is on a different set of disks than the user database. However, this increases the amount of disk space that is used during the index build.
OFF
The intermediate sort results are stored in the same database as the index.
In addition to the space required in the user database to create the index, tempdb must have about the same amount of additional space to hold the intermediate sort results. For more information, see SORT_IN_TEMPDB Option For Indexes.
In backward compatible syntax, WITH SORT_IN_TEMPDB is equivalent to WITH SORT_IN_TEMPDB = ON.
Use COMPRESSION where possible
This functionality merely adds DATA_COMPRESSION=PAGE to the CREATE statement without checking if the SQL Server version allows it.
New index PREFIX
when AIM advices new indexes this is the prefix added to the index name.
A new index name always has a datetime component in it to make the indexes unique.
New index SUFFIX
when AIM advices new indexes this is the suffix added to the index name.
A new index name always has a datetime component in it to make the indexes unique.